



Systemadministration- Der Bootvorgang |
| Übersicht |


|
Wenn nach dem Einschalten des Rechners endlich der Anmeldebildschirm erscheint, ist nicht nur einige Zeit verstrichen, sondern es sind auch einige komplexe Vorgänge abgelaufen.
Der Schwerpunkt dieses Buches soll bei Linux liegen, dennoch wollen wir Ihnen die Arbeitsweise des BIOS Ihres Rechners und die prinzipiellen Funktionen eines Bootloaders nicht vorenthalten.
Nach dem einführenden Abhandlungen bringen wir etwas Licht in die zahlreichen Ausgaben, die der Kernel während des Bootens auf den Bildschirm schreibt. Leider beschreiten die verschiedenen Distributionen schon in dieser frühen Phase eigene Wege, so dass wir hin und wieder auf sehr spezifische Details eingehen müssen.
Es gibt Situationen, in denen die üblichen Mechanismen versagen. Im Falle des Bootvorganges werden wir deshalb auf die Möglichkeit des Startens von Rechnern eingehen, deren Hardware-Konfiguration dem Kernel vorab nicht bekannt ist. Was es damit auf sich hat, erfahren Sie unter Alternative Konzepte - Ramdisks.
Ein gänzlich anderes Bootvorgehen ist notwendig, falls der eigene Rechner über keinerlei Festplatte verfügt, das System also erst über das Netz geladen werden muss.
| BIOS Selbsttest |
|
Nach Einschalten oder Reset des Rechners beginnt dieser mit der Programmausführung an einer festgelegten Adresse (f000:fff0h). An jener Position befindet sich immer das BIOS, das sogleich zu den Initialisierungs- und Testroutinen, dem so genannten Power On Self Test POST, springt.
POST arbeitet in zwei Schritten:
- Test und Initialisierung zentraler Hardware: hierzu gehören die CPU, BIOS-ROM (Bildung einer Prüfsumme), DMA-Controller, Tastatur, die ersten 64k des RAMs, Interrupt-und Cache-Controller
- Test und Initialisierung von System-Erweiterungen: hierzu zählen der RAM über 64k, die Schnittstellen, Disketten- und Festplatten-Controller
Des Weiteren werden nach peripheren ROM-Erweiterungen wie dem Video-ROM gesucht und diese initialisiert. Bei SCSI-Systemen mit eigenem BIOS wird dieses ebenso bearbeitet.
Tritt in dieser Phase ein Fehler auf, wird entweder eine Meldung auf dem Bildschirm ausgegeben oder das BIOS macht mit Hilfe einer Tonfolge auf das Problem aufmerksam. Für bestimmte Fehler sind genaue Signale vorgeschrieben:
| Ton | Defekt |
|---|---|
| Anhaltend (oder kein Ton) | Netzteil |
| Einmal lang | kein DRAM-Refresh |
| Einmal lang, einmal kurz | Mainboard |
| Einmal lang, zweimal kurz | Video-Controller oder Bildschirmspeicher |
| Dreimal kurz | RAM |
| Einmal kurz | Laufwerk oder Video-Controller |
Sind alle Tests positiv verlaufen, sucht das BIOS auf den Bootgeräten nach einer gültigen Bootsequenz. Bootgeräte können eine Diskette, eine Festplatte, das CD-ROM-Laufwerk und die Netzwerkkarte sein. Welche Bootmedien durchsucht werden und die Reihenfolge, in der das BIOS die Geräte durchsucht, kann im CMOS-Setup eingestellt werden. Der erste gefundene Bootkode wird geladen und gestartet.
| Bootloader |
|
Im weiteren Verlauf lädt das BIOS den Mbr (Master Boot Record) des ersten eingetragenen Bootmediums. Der Mbr enthält neben der Partitionstabelle mit den Koordinaten der maximal 4 primären (bzw. maximal 3 primären und einer erweiterten) Partitionen ein kleines Programm (446 Bytes), das die Auswertung der Daten der Partitionstabelle übernimmt. Ist eine dieser Partitionen mittels eines bootable Flags markiert, wird deren Bootsektor (der erste Sektor dieser Partition) angesprungen und der dortige Kode ausgeführt. Fehlt eine Markierung, so fährt das BIOS mit dem Laden des Mbr vom nächsten Bootmedium fort. Ist dagegen der Bootkode einer »bootable« Partition ungültig, stoppt der Bootvorgang mit einer Fehlermeldung (bei einer Diskette wird bspw. zu deren Wechsel aufgefordert).
Die allgemeine Aufgabe des Bootkodes ist das Laden des Betriebssystems. Systeme, die nur einen solchen intialen Bootkode mit sich bringen, besitzen meist die unangenehme Eigenschaft, dass sie nach der Installation ungefragt das bootable Flag im Mbr auf »ihre« Partition umbiegen und daher das Booten von bereits installierten »Fremdsystemen« verhindern.
Ein Bootkode, der hingegen das Laden mehrerer Betriebssysteme unterstützt, wird als Bootloader oder Bootmanager bezeichnet. Linux selbst ist zwar nicht auf einen Bootloader angewiesen, mit Ausnahme des Starts von einem Wechselmedium (Diskette, CDROM) wird dennoch auf einen solchen zurückgegriffen. Der Standard-Loader von Linux - Lilo - kann sowohl das kleine Programm im Mbr ersetzen als auch im Bootsektor einer Partition liegen. In ersterem Fall lädt das BIOS direkt den Bootloader; in letzterem Fall muss die den Lilo enthaltene Partition in der Partitionstabelle mit dem »bootable« Flag versehen sein.
Bootloader vermögen oft weit mehr als nur das Laden eines Betriebssystems. So können sie den Start der Systeme mit einem Passwort schützen oder Parameter an das System übergeben, die dessen Arbeit dann beeinflussen.
Bei einer solch umfangreichen Funktionalität ist es leicht nachvollziehbar, dass der gesamte Kode eines Bootloaders nicht in die dafür reservierten 512 Bytes eines Bootsektors passt. Zumal von diesem Speicherplatz weitere 2 Bytes für eine »Magic Number« (AA55; sie markiert den Sektor als gültigen Bootkode) und - im Falle des Mbr - noch 64 Bytes für die Partitionstabelle abzuziehen sind. Deshalb werden heutige Bootloader in zwei Stufen realisiert, wobei die erste Stufe im Bootsektor bzw. im Mbr einzig die Aufgabe hat, die zweite, auf der Festplatte liegende Stufe, in den Hauptspeicher zu laden.
Ein Bootloader kennt nun die Speicherplätze der von ihm verwalteten Betriebssysteme und wird das Auserwählte in den Hauptspeicher laden.
Im Falle von Linux übernimmt mit der Meldung
| Uncompressing Linux... |
der Kernel die Kontrolle über den Rechner.
| Initialisierung des Kernels |
|
Jeder Kernel besitzt eine Einsprungmarke, an der er mit seiner Arbeit beginnt. Zunächst bewegt sich seine Tätigkeit sehr nahe an der Hardware, er ermittelt aus dem BIOS elementare Parameter und schaltet den Prozessor in den Protected Mode. Die nächsten Schritte betreffen die Initialisierung der Speicherverwaltung (MMU), des eventuell vorhandenen Coprozessors und der Interruptcontroller sowie die Erzeugung einer minimalen Umgebung.
Alles Bisherige realisierten Assembler-Routinen, also Programmteile, die in der Sprache des Prozessors geschrieben sind. Die weiteren Funktionen sind weniger architekturabhängig und deswegen in der Sprache C implementiert.
Im nächsten Schritt erfolgt die Initialisierung aller Kernelteile. Hierzu zählen die virtuelle Speicherverwaltung, die Interruptroutinen, die Zeitgeber, der Scheduler, der für die Zuteilung der CPU an die Prozesse verantwortlich ist. Weiter wird das Dateisystem initialisiert, verschiedene Kernelpuffer angelegt, Netzwerkschnittstellen und die Ressourcen der Interprozesskommunikation...
Was jetzt läuft, wird als Idle-Prozess, der Prozess mit der Prozessnummer 0, bezeichnet. Genau genommen ist er der erste Prozess im System, jedoch erledigt er rasch seine Aufgabe und ist dann nicht mehr sichtbar, obwohl er immer dann aktiv wird, wenn eigentlich nichts zu tun ist. Dennoch hat der Prozess mit der Nummer 0 eine wichtige Aufgabe: er ist derjenige, der den »ersten« Prozess ins Leben ruft. Der init -Prozess gilt allgemein als erster Prozess im System, da er der Ursprung aller weiteren Prozessfamilien ist. Bei Multiprozessorsystemen übernimmt der Prozess 0 die Initialisierung der weiteren Prozessoren.
init bekennt sich sogleich zu seiner absoluten Alleinherrschaft und sperrt für alle anderen Interessenten (Prozess 0) den Zugang zu den Kernelfunktionen. In den kommenden Schritten darf ihm einfach niemand dazwischen funken. init initialisiert weiter. Der Name ist Programm... Worum es sich konkret handelt, hängt von der Konfiguration des Kernels ab. Übliche Punkte sind die (PCI-) Geräte und Sockets. Die ersten Dämonen werden ins Leben gerufen, der bdflush zur Synchronisation von Cache und Dateisystem und der kswapd zur Verwaltung des Swapspeichers. Dem Kernel werden nun die unterstützten Binärformate und Dateisysteme bekannt gegeben und anschließend wird versucht, das Root-Dateisystem zu mounten (dieses ist im Kernel fest verankert; es kann per Bootoption überschrieben werden). Ist bislang nichts schief gegangen, lässt init auch den anderen Prozessen eine Chance, indem es den Kernel wieder frei gibt.
Er selbst fährt mit dem Eröffnen einer Konsole für die Ein- und Ausgaben fort. Gelingt dies nicht, ist die Ausgabe "Warning: unable to open an initial console." die Folge.
Abschließend wird das Programm init auf der Platte gesucht. Die Reihenfolge der betrachteten Verzeichnisse ist
- /sbin/init
- /etc/init
- /bin/init
Der rufende Prozess führt den Systemruf exec() aus, so dass dessen Programm vom Neuen überlagert wird. Scheitert der erste exec()-Aufruf, so erreicht das originale Programm den nächsten Aufruf usw.
Falls kein Programm init gefunden wurde, wird abschließend versucht, die Shell /bin/sh zu starten, um dem Administrator eine Reparatur des Systems zu ermöglichen. Gelingt auch dieses nicht, hält der Kernel mit der Ausschrift "No init found. Try passing init= option to kernel." an.
| Der erste Prozess |
|
Bis dato konnte der Administrator nur über Optionen, die dem Kernel auf der Bootzeile angegeben werden, oder durch Erzeugen eines neuen Kernels den Bootvorgang steuern. Mit dem Laden des Programms init in die Umgebung des ersten Prozesses beginnt die eigentliche administrative Einflussnahme.
Bis auf wenige Ausnahmen verwenden nahezu alle aktuellen Distributionen das Startverfahren nach System V. Jede Komponente, die während des Systemstarts aktiviert werden soll, wird durch ein eigenes Skript beschrieben. Die verschiedenen Skripte können in geeigneter Reihenfolge abgearbeitet werden, in Abhängigkeit der tatsächlich zum Einsatz kommenden Teilmenge der Skripte gelangt das System in einen unterschiedlichen Zustand, das so genannten Runlevel.
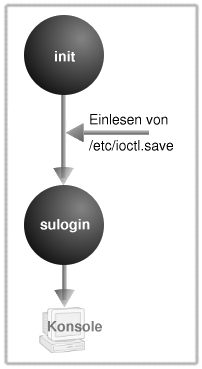
Abbildung 1: Start im Single User Mode |
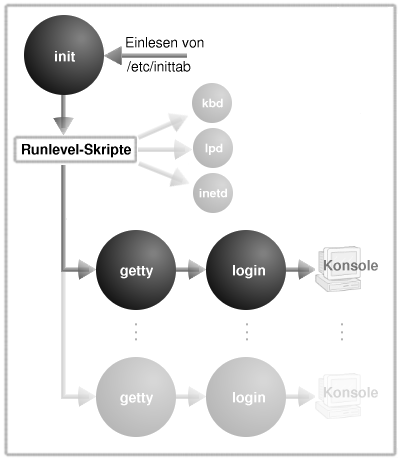
Abbildung 2: Start im Multi User Mode |
Wenn init mit seiner Arbeit beginnt, sucht es zunächst nach seiner Konfigurationsdatei /etc/inittab. Für den Fall, dass diese nicht existiert oder kein mit initdefault beginnender Eintrag enthalten ist, fordert init zur Eingabe des zu startenden Runlevels auf.
Bei einer fehlenden Datei /etc/inittab ist nun nur der Start im Single User Modus (Runlevel 1, S bzw. s) zulässig, da zum Start im Multi User Modus weitere Informationen benötigt werden, welche die Konfigurationsdatei enthält. Im Single User Modus entnimmt init der Datei /etc/ioctl.save (sofern vorhanden, sonst gelten Default-Werte und die Datei wird erzeugt) die Einstellungen für das Terminal und startet das Programm /sbin/sulogin, das mit der bereits eröffneten Konsole "/dev/console" verbunden wird. In diesem Modus kann sich einzig der Systemverwalter anmelden, es laufen auch nur die zwingend benötigten Prozesse, so dass alle Ressourcen dem Administrator zur Verfügung stehen. Der Modus dient vorrangig der Pflege des Systems, so wäre es bspw. fatal, wenn ein Benutzer während der Reparatur des Dateisystems schreibenden Zugriff auf dieses erhielte.
Im Falle des Multi User Modus kommt auf init eine Menge weiterer Arbeit zu. In einem nächsten Schritt lässt init alle dem jeweiligen Runlevel zugeordneten Skripte von einem Shellskript namens rc starten. Das ist der Zeitpunkt, wenn die zahlreichen Meldungen über gestartete Dämonenprozesse über den Bildschirm flimmern. Ist das aktuelle Runlevel erreicht, startet init eine Reihe von getty-Prozessen, die wiederum auf der ihnen zugedachten Konsole das Kommando login ausführen, welches letztlich die Aufforderung zur Anmeldung auf den Bildschirm bringt.
| Die Datei /etc/inittab |
|
Jede Zeile der zentralen Konfigurationsdatei des init-Prozesses besitzt folgenden Aufbau:
| ID:Runlevel:Aktion:Prozess |
ID
Runlevel
Aktion
Hier wird das »Wie« des Prozessstarts angegeben, die möglichen Einträge lauten:
respawn
wait
once
boot
off
ondemand
initdefault
sysinit
powerwait
powerfail
powerokwait
powerfailnow
ctrlaltdel
kbrequest
Prozess
Nach all der Theorie verfolgen wir, was init tatsächlich der Reihe nach vollführt.
Als erstes durchsucht init die Tabelle /etc/inittab nach einem Eintrag, dessen Aktion auf sysinit steht. Ein solcher Eintrag dient i.A. zur Erledigung der »Hausaufgaben«, wie dem Überprüfen und Mounten der Dateisysteme, Setzen der Systemzeit, Initialisierung des Swap-Speichers, also Arbeiten, die für jedes Runlevel von Nöten sind. Ein solcher Eintrag ist typisch für die meisten RedHat-basierenden Distributionen:
| si::sysinit:/etc/rc.d/rc.sysinit |
Debian nutzt den »sysinit«-Eintrag, um die Skripte des Verzeichnisses /etc/init.d/rcS.d zu verarbeiten:
| si::sysinit:/etc/init.d/rcS |
Ein gänzlich anderes Verhalten legt SuSE-Linux vor, das die globalen Initialisierungen einem bootwait-Eintrag vollziehen lässt:
|
# SuSE <= 7.0 si:I:bootwait:/sbin/init.d/boot # SuSE >= 7.1 si:I:bootwait:/etc/init.d/boot |
boot und bootwait sind die folgenden Einträge, nach denen init die Datei durchforstet. Wie man sein System letztlich konfiguriert, ist Geschmackssache. Verwendet man ein einziges Skript, das die allgemeinen Einstellungen regelt, so spielt es keine Rolle, ob es mit einem sysinit-, oder bootwait- Eintrag in den Bootprozess eingebunden wird. Bei Verwendung mehrerer Skripte kann mit sysinit die Verarbeitung eines Skriptes vor den anderen erzwungen werden. Beide Einträge erfordern das Warten von init, bis die Prozesse ihre Tätigkeit abgeschlossen haben.
Der für den Administrator wohl interessanteste Eintrag ist die initdefault-Zeile, die Linux anweist, in einem konkreten Runlevel zu starten:
| id:2:initdefault: |
Der zweite Eintrag bestimmt dabei das zu aktivierende Level. Entgegen den anderen Zeilen der Datei darf hier nur ein einziges Level angegeben werden. Möchte man permanent ein anderes Runlevel einrichten, so kann dieser Wert von Hand editiert oder mittels (distributionsspezifischer) Werkzeuge gesetzt werden:
- Debian: Es geht doch nichts über die Handarbeit...
- RedHat: linuxconf
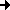 Verwaltung
Verschiedene Dienste
Initiale Systemdienste
Verwaltung
Verschiedene Dienste
Initiale Systemdienste - SuSE: yast
Administration des Systems
Login-Konfiguration
Login-Oberfläche (ein Wechsel ist nur
zwischen Runlevel 2 und 3 möglich)
Für jedes von der Distribution definierte Runlevel muss ein Eintrag in der /etc/inittab vorhanden sein. Welche Distribution welches Runlevel mit welcher Eigenschaft versieht, soll Thema des nachfolgenden Abschnitts sein. Hier betrachten wir nur eine exemplarische Zeile aus einem SuSE-System (Versionen vor 7.1):
| l0:0:wait:/sbin/init.d/rc 0 |
Die anderen Distributionen unterscheiden sich zumeist einzig in der Lage des Skripts rc. Unser Beispieleintrag betrifft das Runlevel 0, jenes, welches i.A. das Anhalten des Systems regelt. Erfolgt ein Wechsel zu diesem Runlevel, so wartet init auf das Ende des Skripts »rc« (wait). rc wird bei jedem Wechsel des Runlevels gerufen, als Argument wird ihm das neue Level übergeben. Die Einträge für alle weiteren Level sind analog aufgebaut.
Um sinnvoll mit dem System arbeiten zu können, muss init noch für die Login-Konsolen Sorge tragen:
| 1:2345:respawn:/sbin/mingetty tty1 |
Wieder sei beispielhaft nur ein Eintrag für einen getty-Prozess auf der ersten Konsole erwähnt. Als Bezeichner (ID) empfiehlt das Manual zu inittab die Nummer des betreffenden Terminals. respawn besagt hier, dass nach dem Ableben des Prozesses (/sbin/mingetty) sofort ein Neuer zu starten ist. Das ist der Grund, warum nach einem logout eine neue Anmeldeaufforderung erscheint.
Unter Linux wird dem normalen Benutzer häufig das Herunterfahren des Systems über den so genannten Affengriff gestattet. Die Reaktion des Systems auf diese Tastenkombination ([Ctrl]-[Alt]-[Del]) wird in der Datei /etc/inittab festgelegt:
| ca::ctrlaltdel:/sbin/shutdown -r -t 4 now |
Im Beispiel reagiert Linux nach 4 Sekunden Verzögerung mit einem Reboot.
Nach einer Modifikation der Datei "/etc/inittab" sollte der init-Prozess seine Konfigurationsdatei neu einlesen. telinit q überredet ihn hierzu.
| Die Runlevel |
|
Der Begriff des Runlevels tauchte in den vorangegangenen Abschnitten wiederholt auf, ohne ihn im Detail diskutiert zu haben. Dies soll nun schleunigst nachgeholt werden.
Ein Runlevel definiert einen Zustand des Unix-Systems. Unter einem Zustand verstehen wir eine bestimmte Konstellation aktiver Prozesse, die während des Bootvorgangs initiiert wurden. So werden in einem Netzwerk-Runlevel zahlreiche Dämonenprozesse gestartet (z.B. inetd, httpd,...), die in einem Modus ohne Netzwerk nicht notwendig sind und demzufolge in dessen Konstellation nicht erscheinen.
Prinzipiell stehen die Runlevel 0 bis 9, a, b, c und s zur Verfügung. 0 und 6 sind dabei von vornherein mit bestimmten Funktionalitäten versehen, die Verwendung der weiteren Level ist stark distributionsabhängig. Traditionell werden die Runlevel 7-9 nicht verwendet, auch a-c sucht man bei den verbreiteten Distributionen vergeblich. »s« wird häufig als Single User Modus verwendet.
Die hinter einem Runlevel stehende Konstellation ist hochgradig konfigurierbar und es steht in der Verantwortung des Administrators, welche Dienste in welchem Zustand im System residieren. Dennoch stellen alle Distributionen mit der Neuinstallation eine brauchbare Konfiguration bereit. Die Runlevel 0 (Systemhalt) und 6 (Reboot) sollten in jeder Linuxdistribution einheitlich belegt sein. Runlevel 1 wird bei Debian, RedHat und SuSE (erst ab 7.3) ebenso einheitlich als Single User Mode konfiguriert. Darüber hinaus unterscheiden sich die Vorgehensweisen der Distributoren.
Debian
Im Runlevel s stehen alle Skripte, die einmalig während des Bootvorgangs abgearbeitet werden müssen (es handelt sich also um kein eigenständiges Runlevel). Diese Skripte werden vor dem eigentlich zu startendem Runlevel ausgeführt, nicht jedoch beim Wechsel der Runlevel im laufenden System (telinit).
Die Runlevel 2-5 werden bei Debian identisch gehandhabt. Was konkret in ihnen geschieht, hängt einzig von der installierten Software ab (ist bspw. der Xdm installiert, wird das grafische Login aktiviert).
Redhat
RedHat kennt das Runlevel 2 als Multiuser ohne Netzwerk. Im Runlevel 3 kommt die Netzwerkfunktionalität hinzu.
Runlevel 4 wird in der Standardinstallation nicht verwendet.
Runlevel 5 ist die »volle Ausbaustufe«; also Multiuser mit Netzwerk und grafischem Login.
SuSE
Ab Version 7.3 entspricht das Startverhalten der SuSE-Distribution dem von RedHat.
In früheren SuSE-Versionen stand Runlevel S für den Single User Modus. Runlevel 1 diente als Multiuser ohne Netzwerk, 2 als Multiuser mit Netzwerk und 3 als Multiuser mit Netzwerk und grafischem Login. Runlevel 4 und 5 wurden nicht verwendet (in 7.2. war 5 identisch zu 3).
Init-Skripte
Zahlreiche Skripte werden in verschiedenen Runleveln benötigt. Man denke nur an den Protokollanten von Linux, den syslogd, dessen Dienste eigentlich immer nützlich sein sollten. Um solche "Init"-Skripte nicht mehrfach im System speichern zu müssen, sammelt man alle in einem einzigen Verzeichnis. Dieses ist:
- "/etc/init.d" bei Debian
- "/etc/rc.d/init.d" bei RedHat
- "/sbin/init.d" bei SuSE <= 7.0
- "/etc/init.d" bei SuSE ab 7.1
Die Namensgebung der einzelnen Skripte verrät oftmals deren Zweck (Beispiel aus RedHat-Linux):
|
user@sonne> ls /etc/rc.d/init.d apmd functions inet linuxconf network random rwhod snmpd arpwatch gpm keytable lpd nfslock routed sendmail syslog atd halt killall named pcmcia rstatd single xfs crond identd kudzu netfs portmap rusersd smb ypbind |
Jedes konfigurierte Runlevel ist im Dateisystem durch ein eigenes Verzeichnis repräsentiert, wobei die Namensgebung rcx.d, x steht für das Runlevel, lautet. Auch hier gehen die Distributionen, was die Lage dieser Verzeichnisse betrifft, eigene Wege:
- "/etc/rcx.d" bei Debian
- "/etc/rcx.d" bei RedHat (ab 7.0 sind dies Links auf gleichnamige Verzeichnisse in /etc/rc.d/)
- "/sbin/init.d/rcx.d" bei SuSE <= 7.0
- "/etc/rc.d/rcx.d" bei SuSE ab 7.1
Namensgebung der Runlevelskripte
Jedes Skript, das nun in einem Runlevel zu starten ist, erscheint als Link unter zwei verschiedenen Namen im Verzeichnis des Runlevels. Dabei ist die Namensgebung der Verweise verbindlich und in unten stehender Abbildung skizziert.

Abbildung 3: Die Namensgebung der Runlevelskripte
Die Linknamen setzen sich aus drei Komponenten zusammen, die das Skript rc bewertet:
- Der erste Buchstabe beschreibt, ob es ein Stoppskript (Buchstabe = K) oder ein Startskript (Buchstabe = S) ist
- Zwei Ziffern bestimmen die Priorität des Skriptes (00 bis 99). Von den Skripten in einem Runlevel werden alle mit kleinerer Nummer vor den Skripten mit höherer Nummer abgearbeitet, somit wird sicher gestellt, dass ein Dienst, der einen anderen zu seiner Arbeit bedingt, erst nach diesem aktiviert wird. Skripte mit identischer Nummer sind voneinander unabhängig und werden entsprechend ihrer alphabetischen Ordnung betrachtet.
- Der Rest ist der »eigentliche« Name und kann beliebig gewählt werden. Normal wird man sich für einen Namen entscheiden, der auf das entsprechende Skript schließen lässt.
Die Arbeitsweise des Skripts rc
Das Resource Control-Skript wird immer mit dem zu startenden Runlevel als Argument aufgerufen, also z.B. "rc 3" oder "rc S". rc bestimmt zunächst das alte Runlevel (der Schritt entfällt beim Systemstart), wechselt in dessen Verzeichnis und liest alle mit einem K beginnenden Links ein. Jedes dieser Skripte wird, entsprechend der durch die Priorität vorgegebenen Reihenfolge, mit dem Argument stop gestartet und auf dessen Terminierung gewartet. Nachdem alle Stoppskripte behandelt wurden, wechselt rc in das Verzeichnis des neuen Runlevels und verfährt analog mit den dortigen S-Links, denen als Argument start mitgegeben wird.
Der Aufbau eines Init-Skripts
Bei den Init-Skripten handelt es sich um nichts anderes als (Bash) Shellskripte. Sie können demzufolge ebenso »von Hand« aufgerufen werden. So ist Root durchaus berechtigt mit:
|
# Beispiel aus RedHat-Linux root@sonne> /etc/rc.d/init.d/network stop root@sonne> /etc/rc.d/init.d/network start |
das gesamte Netzwerk zunächst herunterzufahren, um es anschließend erneut zu starten (z.B. nach Änderungen in der Konfiguration). Darüber hinaus kennen die meisten Skripte weitere Argumente:
- probe testet, ob seit dem letzten Neustart des Dienstes dessen Konfigurationsdatei(en) modifiziert wurde(n)
- reload arbeitet wie "restart"
- restart Neustart eines Dienstes (wie "stop" mit anschließendem "start")
- status zeigt Statusinformationen an (bei Samba z.B. die aktiven Verbindungen)
Als Beispiel dient ein Skript, das den X-Font-Server xfs in einem RedHat-System startet:
|
#!/bin/sh # # xfs: Starts the X Font Server # # Version: @(#) /etc/rc.d/init.d/xfs 1.6 # # chkconfig: 2345 90 10 # description: Starts and stops the X Font Server at boot time and shutdown. # # processname: xfs # config: /etc/X11/fs/config # hide: true # Source function library. . /etc/rc.d/init.d/functions # See how we were called. case "$1" in start) echo -n "Starting X Font Server: " rm -fr /tmp/.font-unix daemon xfs -droppriv -daemon -port -1 touch /var/lock/subsys/xfs echo ;; stop) echo -n "Shutting down X Font Server: " killproc xfs rm -f /var/lock/subsys/xfs echo ;; status) status xfs ;; restart) echo -n "Restarting X Font Server. " if [ -f /var/lock/subsys/xfs ]; then killproc xfs -USR1 else rm -fr /tmp/.font-unix daemon xfs -droppriv -daemon -port -1 touch /var/lock/subsys/xfs fi echo ;; *) echo "*** Usage: xfs {start|stop|status|restart}" exit 1 esac exit 0 |
Mit etwas Kenntnis zur Shellprogrammierung sollte der Leser in der Lage, eigene Init-Skripte zu verfassen und somit zusätzliche Dienste den Runleveln hinzuzufügen.
Wechsel des Runlevels
Im laufenden Betrieb ist der Wechsel eines Runlevels ebenso möglich. Denkbar ist, dass Root das System im Single User Modus startet, irgendwelche administrativen Eingriffe vornimmt und nachfolgend Linux in den »normalen« Multi User Modus mit Netzwerk versetzt. Ein solcher »online«-Wechsel ist wesentlich schneller vollzogen als ein Reboot. Der Systemadministrator behilft sich hierzu des Kommandos telinit (meist ein Link auf "/sbin/init"), das er mit dem neuen Runlevel als Argument startet:
| root@sonne> telinit 3 |
Bearbeiten der Runlevelskripte
Das Hinzufügen und Entfernen von Skripten zu einem Runlevel kann in althergebrachter Manier per Hand erfolgen. Etwas komfortabler geht es mit dem Editor ksysv vom KDE-Projekt (Abbildung 4), der per Drag&Drop die Verwaltung der Links ermöglicht. Per Dialogboxen arbeitet in RedHat-System ntsysv.
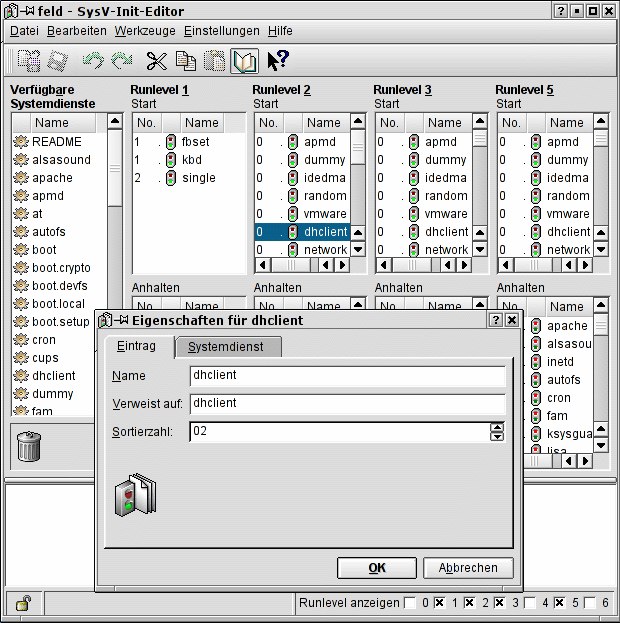
Abbildung 4: Der KDE-Runlevel-Editor
Achtung: Unter SuSE-Linux genügt das alleinige Hinzufügen der Links bei vorgefertigten Diensten nicht, da die SuSE-Skripte intern die Datei /etc/rc.config einlesen und dortige Variablen auswerten. Sie müssen die entsprechende Variable in /etc/rc.config (bspw. »START_XFS« für den X-Font-Server »xfs«) entweder von Hand oder per »Yast1« auf »yes« setzen.
| Alternative Konzepte - Ramdisks |
|
Um auf Hardware zugreifen zu können, benötigt Linux entsprechende Treiber. Diese Treiber können entweder direkt im Kernel integriert sein oder als dynamisch ladbare Module vorliegen. Die Menge der fest einkompilierten Treiber ist allerdings beschränkt, da in der Ladephase des Kernels dieser vollständig in den Hauptspeicher passen muss. Zum Zeitpunkt des Ladens (gewöhnlich nimmt dies ein Bootloader vor) befindet sich der Rechner allerdings noch im so genannten Real Modus, d.h. der adressierbare Hauptspeicher und damit auch die Größe des Kernels sind begrenzt (aus DOS-Zeiten sind Ihnen sicherlich 640kByte und die Tricks mit EMS und XMS noch ein Begriff).
Um Module verwenden zu können, müssen diese irgendwo im Dateisystem liegen. Der Kernel muss auf das Dateisystem zugreifen können, womit zumindest die Treiber für das entsprechende Dateisystem und für das Gerät, auf dem dieses liegt (Festplatten-Controller, SCSI-Adapter...) fest im Kernel enthalten sein müssen. Nun gibt es aber eine ganze Reihe von Controllern, über die die Festplatten angesprochen werden, und jeder Controller benötigt einen anderen Treiber. Ein universeller Kernel, wie er bspw. bei der Installation erforderlich ist, müsste also alle erdenklichen Treiber enthalten, um auf allen erdenklichen Hardware-Konstellationen laufen zu können. Ein solcher Kernel wäre vermutlich wieder zu groß um in den Hauptspeicher zu passen... womit wir der Lösung des Problems kein Stück näher gerückt wären.
Und hier setzen initrd und Ramdisks an, die den eigentlichen Bootvorgang in zwei Schritten realisieren. Eine Ramdisk belegt einen Teil des Hauptspeichers (RAM) und legt in diesem ein Dateisystem an (DISK). Ein Bootloader legt nun im Speicher hintereinander die Datei »initrd« und den Kernel ab. Der nachfolgend zu startende (minimale) Kernel enthält nun den Treiber, um den Inhalt von »initrd« in eine Ramdisk zu entpacken und diese als sein Root-Dateisystem zu mounten. Die ursprüngliche Datei »initrd« wird aus dem Hauptspeicher entfernt.
In der Ramdisk sollte nun eine Datei /linuxrc existieren, die nun abgearbeitet wird (i.A. beinhaltet diese ausführbare Datei Schritte zum Testen der Hardware und zum Laden der notwendigen Module zum Zugriff auf die erkannten Geräte). Sobald die Datei abgearbeitet wurde, wird das »eigentliche« Dateisystem als Wurzelverzeichnis gemountet. Existiert in diesem das Verzeichnis »/initrd«, wird die Ramdisk dorthin verschoben, anderenfalls wird sie abgehangen.
Des Weiteren wird mit dem Start von /sbin/init wie »üblich« fortgefahren.
Das Erstellen einer Ramdisk
An dieser Stelle können wir das Thema nicht erschöpfend darstellen. Deshalb werden wir die erforderlichen Schritte durchlaufen, um eine funktionsfähige Ramdisk zu erstellen. Diese wird nichts anderes tun, als den Benutzer während des Systemstarts zu einer Eingabe aufzufordern. Das Beispiel wird hoffentlich die Klippen beim Vorgehen verdeutlichen und kann als Basis für eigene Experimente dienen.
Ramdisk erstellen und mounten
Sie benötigen ein Dateisystem. Möglich wären:
Verwendung einer Diskette
|
# Formatieren der Diskette (ext2) root@sonne> mke2fs -m0 /dev/fd0 # Mounten der Diskette root@sonne> mount /dev/fd0 /mnt |
Verwendung des Loopback-Devices (dies muss der Kernel unterstützen!)
|
# Erstellen einer Datei (hier 4M groß) root@sonne> dd if=/dev/zero of=initrd bs=1k count=4096 # Anlegen des Dateisystems root@sonne> mk2fs -m0 initrd # Mounten der Datei als Loopback-Device root@sonne> mount initrd /mnt -t ext2 -o loop |
Verwendung eines Teils des Hauptspeichers über das Device /dev/ram
|
# Dateisystem mit 4096 1k-Blöcken root@sonne> mke2fs -m0 /dev/ram -b 1024 4096 # Mounten root@sonne> mount /dev/ram /mnt |
Anmerkung: Die Größe des Dateisystems hängt natürlich von den darin zu installierenden Dateien (Programme, Bibliotheken) ab. In bestimmten Situationen kann die Kapazität einer Diskette schon zu gering sein. Das nachfolgende Beispiel benötigt z.B. ca. 2M!
Dateien kopieren
Dieser Schritt erfordert die sorgfältigsten Überlegungen und ist Quelle zahlreicher Fehler. Es gilt alle Programme, Bibliotheken, Devices und Konfigurationsdateien zu erzeugen, die von der später auszuführenden Datei »linuxrc« benötigt werden. Greifen Sie auf nur sehr wenige Programme zurück, sollten Sie statisch kompilierte Versionen verwenden, da Sie dann die speicherintensiven Bibliotheken einsparen. Allerdings bedarf es einiger Tests, bei welchen Zusammenstellungen statisch und wo dynamische gelinkte Versionen weniger Ressourcen verzehren. Überzeugen Sie sich bei dynamischen Programmen, dass sämtliche Bibliotheken ebenfalls vorhanden sind. Das Notwendige verrät Ihnen der Linker:
|
# Welche Bibliotheken benötigt die dynamische Version der bash? root@sonne> ldd bash libncurses.so.4 => /lib/libncurses.so.4 (0x4001d000) libdl.so.2 => /lib/libdl.so.2 (0x4005c000) libc.so.6 => /lib/libc.so.6 (0x4005f000) /lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000) |
Im neuen Dateisystem (das unter »/mnt« gemountet ist) sollten zumindest folgende Verzeichnisse existieren:
|
root@sonne> ls -l /mnt total 16 drwxr-xr-x 2 root root 1024 Jun 2 13:57 /mnt/bin drwxr-xr-x 2 root root 1024 Jun 2 13:47 /mnt/dev drwxr-xr-x 2 root root 1024 May 20 07:43 /mnt/etc drwxr-xr-x 2 root root 1024 May 27 07:57 /mnt/lib drwxr-xr-x 2 root root 12288 May 27 08:08 /mnt/lost+found |
In »realen« Ramdisks ist die Verzeichnisstruktur komplexer. Meist existieren die vom Filesystem Hierarchie Standard vorgeschriebenen Verzeichnisse. Für unsere Zwecke reichen die oben benannten Einträge aus.
Unsere Demonstrations-Ramdisk benötigt einzig eine Shell »bash« und das Kommando »echo«. Wir verwenden die dynamischen Varianten der Programme und legen zusätzlich den Link «sh« auf »bash« an (anstelle der »bash« könnte man auch eine der »schlanken« Shells wie die »ash« verwenden):
|
root@sonne> ls -l /mnt/bin total 497 -rwxr-xr-x 1 root root 490932 Nov 9 1999 /mnt/bin/bash -rwxr-xr-x 1 root root 7972 Nov 22 1999 /mnt/bin/echo lrwxrwxrwx 1 root root 4 Jan 27 2000 /mnt/bin/sh -> bash |
Als einziges Device benötigen wir /dev/console. Fehlt dieses, würde der Kernel mit Warning: unable to open an initial console. seinen Dienst quittieren. Möchten Sie auf Hardware zugreifen, müssen Sie die Devices für diese anlegen. Im Falle von /dev/console geht man wie folgt vor:
|
# Device anlegen mit "mknod", die Argumente bedeuten: # "c" = character # "5" = Hauptgerätenummer # "1" = Nebengerätenummer: root@sonne> mknod /mnt/dev/console c 5 1 # Default-Rechte ändern: root@sonne> chmod 622 /mnt/dev/console root@sonne> ls -l /mnt/dev crw--w--w- 1 root root 5, 1 Sep 1 09:25 /mnt/dev/console |
Beim Anlegen weiterer Devices entnehmen Sie die notwendigen Haupt- und Nebengerätenummern der Datei »/usr/src/linux/Documentation/devices.txt«. Bei einem blockweise arbeitenden Gerät verwenden Sie anstatt »c« ein »b«.
Da wir dynamische Programme verwenden, muss dem dynamischen Linker/Loader ld.so mitgeteilt werden, in welchen Pfaden er die Bibliotheken suchen soll. Die kompilierten Pfade beinhaltet die Datei »/etc/ld.so.cache«, die wir in unser »etc«-Verzeichnis kopieren:
|
root@sonne> ls -l /mnt/etc -rw-r--r-- 1 root root 43258 Sep 1 09:21 /mnt/etc/ld.so.cache |
Schließlich benötigen wir noch die Bibliothek des dynamischen Linkers und Loaders »ld-linux.so.Versionsnummer« und alle von den Programmen »bash« und «echo« benötigten Bibliotheken. Damit sieht der Inhalt des Verzeichnisses »lib« wie folgt aus:
|
root@sonne> ls -l /mnt/lib -rwxr-xr-x 1 root root 360274 Jan 27 1999 /lib/ld-2.1.2.so lrwxrwxrwx 1 root root 11 Jan 27 2000 /lib/ld-linux.so.1 -> ld-2.linux.so.2 lrwxrwxrwx 1 root root 11 Jan 27 2000 /lib/ld-linux.so.2 -> ld-2.1.2.so lrwxrwxrwx 1 root root 11 Jan 27 2000 /lib/libc.so.5 -> libc.so.6 -rwxr-xr-x 1 root root 4223971 Jan 27 1999 /lib/libc.so.6 -rwxr-xr-x 1 root root 75167 Jan 27 1999 /lib/libdl.so.2 lrwxrwxrwx 1 root root 11 Jan 27 2000 /lib/libncurses.so -> libncurses.so.4 lrwxrwxrwx 1 root root 11 Jan 27 2000 /lib/libncurses.so.4 -> libncurses.so.4.2 -rwxr-xr-x 1 root root 526454 Jan 27 1999 /lib/libncurses.so.4.2 |
Manche Programme erwarten bestimmte Versionen einer Bibliothek. Meist enthalten die neueren Bibliotheken dieselben Schnittstellen wie ihre Vorgänger, so dass es genügt, einen Link unter dem alten Namen anzulegen (dies klappt leider nicht immer!). Inwiefern Sie tatsächlich obige Links benötigen, hängt von den konkreten Versionen der von Ihnen verwendeten Programme ab.
linuxrc
Diese ausführbare Datei befindet sich in der Wurzel des neuen Dateisystems und wird automatisch gestartet. Bei ihr wird es sich zumeist um ein Shellskript handeln, das alle Schritte, die innerhalb der Ramdisk auszuführen sind, beinhaltet. Es handelt sich quasi um die zentrale Steuerdatei; mit ihrer Beendigung fährt der Kernel mit der »normalen« Bootsequenz fort (Mounten des eigentlichen Rootverzeichnisses und Start von »init«). Unser einfaches Beispiel soll einzig einen Text ausgeben und auf eine beliebige Eingabe warten.
|
root@sonne> cat /mnt/linuxrc #!/bin/sh echo "Die Datei linuxrc wird ausgefuehrt" read # Execute-Rechte setzen: root@sonne> chmod a+x /mnt/linuxrc |
Zum Abschluss ist das gemountete Dateisystem abzuhängen und das »Image« in eine Datei (vorteilhaft im Verzeichnis /boot) zu kopieren:
|
root@sonne> umount /mnt # Kopieren: falls Sie eine Diskette verwendet haben: root@sonne> dd if=/dev/fd0 of=/boot/initrd # Kopieren: falls Sie ein Loopback-Device verwendet haben: root@sonne> cp initrd /boot/ # Kopieren: falls Sie /dev/ram verwendet haben: root@sonne> dd if=/dev/ram bs=1k count=4096 of=/boot/initrd # Eine Ramdisk sollte freigegeben werden: root@sonne> freeramdisk /dev/ram |
Überzeugen Sie sich noch, dass das Device /dev/initrd existiert:
|
root@sonne> ls -l /dev/initrd brw-rw---- 1 root disk 1, 250 Jan 27 2000 /dev/initrd |
Zu Testzwecken ist es günstig, wenn Sie ein Verzeichnis »/initrd« erzeugen. In dieses wird nach dem Booten die Ramdisk gemountet und kann somit einfach modifiziert werden.
Der Kernel
Eventuell müssen Sie erst einen neuen Kernel generieren, um diesen zur Verwendung einen initialen Ramdisk vorzubereiten. Aktivieren Sie auf jeden Fall die Optionen:
- RAM disk support
- Initial RAM disk (initrd) support
Bootloader
Beim Bootloader sind Sie entweder auf Lilo, LOADLIN oder Chos angewiesen. Alle drei unterstützen die Verwendung von initrd. Tragen Sie in die Konfigurationsdateien des von Ihnen verwendeten Bootmanagers die Zeile "initrd=/boot/initrd" ein und installieren Sie den Bootsektor neu. Das genaue Vorgehen finden Sie im Abschnitt Bootmanager beschrieben.
| Alternative Konzepte - Booten übers Netz |

|
Das dritte hier vorgestellte Bootkonzept tangiert zahlreiche Aspekte der Netzwerkadministration. Wir beschränken uns an dieser Stelle auf eine motivierende Einleitung und werden die Schritte zur Konfiguration einzig benennen. Die konkreten Realisierungen zur Bereitstellung notwendiger Dienste wird man im Abschnitt Netzwerk-Dienste finden.
Beim Booten übers Netz besitzen die Clients einzig ein minimales Programm, das in der Lage ist, während des Bootens einen entsprechenden Serverrechner im Netzwerk zu kontaktieren und sein Root-Dateisystem von diesem zu importieren. Das Vorgehen ermöglicht bspw. den kostengünstigen Aufbau eines ganzen Rechner-Pools, denn auf Clientseite kann sowohl auf Festplatten als auch auf Disketten- oder CDROM-Laufwerke verzichtet werden. Mit einem schnellen Netzwerk (100 MBit), mittelprächtigem Prozessor (kleiner Pentium) und relativ bescheidenem Hauptspeicherausbau (32 MB) wird ein Anwender an einem Client kaum einen Performance-Unterschied feststellen (im Gegenzug sollte der Server mit reichlich Leistung aufwarten). Ein nicht unwesentlicher Aspekt ist die nun einfache Wartung der Software, da diese an einem Ort (Server) konzentriert ist und ein Update damit transparent für alle Clients ist.
Der Client
Der Client benötigt zunächst den Bootkode, damit er während des Hochfahrens auf einen Server zugreifen kann. Der übliche Weg ist, diesen Kode in einem EPROM (Erasable Programmable Read Only Memory) auf der Netzwerkkarte zu halten. Den Kode selbst erhält man u.a. mit den freien Paketen »Etherboot« (aktuelle Version 4.6.6) oder »Netboot« geliefert, allerdings besteht das Problem des Beschreibens des EPROMs, wofür es eines bestimmten Gerätes bedarf. Alternativ kann zum Booten eine Diskette verwendet werden.
Der Bootkode enthält nun den Treiber für die jeweilige Netzwerkkarte sowie die Unterstützung der Protokolle BOOTP (oder DHCP) und TFTP.
BOOTP dient nun der Feststellung der IP-Adresse des lokalen Rechners. Denn da dieser über keinerlei permanenten Speicher verfügt (außer dem EPROM), kann er die ihm zugewiesene IP-Adresse nicht wissen. Zum Glück besitzt jede Ethernet-Karte eine weltweit einmalige Adresse. Ein Client sendet also eine BOOTP-Anfrage per Broadcast (denn die Adresse des Servers kennt er ebenso wenig) ins Netz. Ein BOOTP-Server sollte mit der dem Client zugeordneten IP-Adresse antworten.
Das Laden des Kernels erfolgt über eine »abgespeckte« Variante des bekannten FTP-Protokolls, dem »Trivial FTP« (TFTP). Hauptmerkmale gegenüber dem normalen FTP sind eine fehlende Authentifizierung und die Verwendung des UDP-Protokolls (anstatt dem TCP) zur Datenübertragung.
Damit ist die Arbeit für den Bootkode erledigt und er wird die Kontrolle dem soeben heruntergeladenen Kernel übergeben. Dieser sollte die Fähigkeit besitzen, sein Root-Dateisystem via NFS (Network File System) von einem Server zu importieren.
Der Server
Für gewöhnlich wird ein Server alle Aufgaben erledigen, aber das ist kein Muss. Der Server muss folgende Dienste erbringen:
- BOOTP-Server: Der Server antwortet auf BOOTP-Anfragen aus dem Netz. Dazu verfügt er über eine Datenbank (/etc/bootptab) mit der Zuordnung von Ethernet- zu IP-Adresse (und ggf. weitere Informationen). Im Falle vom Booten übers Netz enthält die Datenbank auch den Namen des Kernels für den Client.
- TFTP-Server: Um dem Client den Kernel zuzuschieben, findet das TFTP-Protokoll Anwendung. Dieser Kernel muss den Treiber für die Netzwerkkarte und die Unterstützung für das Root-Dateisystem via NFS beinhalten (keine Module). Außerdem muss ihm ein bestimmter Header voranstehen, der mit dem Kommando »mknbi-linux« erzeugt wird.
- NFS-Server: Der Server muss ein Verzeichnis an den Client exportieren, das diesem als Wurzelverzeichnis dient. Aus Sicherheitsgründen sollte es sich nicht um das Wurzelverzeichnis des Servers handeln, sondern unter /tftpboot/Client-IP-Adresse liegen.

 Korrekturen, Hinweise?
Korrekturen, Hinweise?